


Forecasting a storm
Part 3 of a series

I’m a researcher at the UC Berkeley Center for Long-Term Cybersecurity where I direct the Daylight Lab. This newsletter is my work as I do it: more than half-baked, less than peer-reviewed. This post is part of a series on building a structural model of the Internet. Find the beginning of that series here.

No one can argue with any empirical certainty about which kinds of events will or will not cause the Internet to collapse. Without empirical arguments, we can’t identify which risks might cause global chaos, let alone which upgrades would help protect against them. So how could we make such arguments?
Only one method has stood the test of time: creating a model of the environment in question and comparing its outputs to empirical observations. By determining the model’s errors and residuals against observed data, researchers improve the model. Rinse and repeat. This process is, broadly speaking, how we learned how to predict the weather.
Business Blackout
Here's an example of this concept executed well. In 2015, Lloyd's bank constructed a scenario called Business Blackout, which assessed the economic impact of widespread Internet failures.
The authors imagined a coordinated cyberattack on a series of power stations in the Northeastern United States. Using various assumptions about dependencies across different industries, they projected both direct and indirect losses, projecting long-term GDP hits to the tune of trillions of dollars.1
Comparing observations to expectations
Business Blackout is a careful and defensible economic analysis. But there’s a critical difference between this model and a weather model. With a weather model, I can make a projection for the next day and go to sleep. I’ll wake up the next morning and see how I did. By repeatedly “diffing” my projection against observation, I can iteratively improve my model. Multiply this process across every inhabited location on Earth, and you’re getting a lot of corrective cycles in.
We can’t compare Business Blackout to anything! What am I supposed to do, wait for a cyberattack on the Northeastern power grid? How are we supposed to improve our ability to make such models in any general sense without some empirical grounding in observed outages?
In general, how can we compare model errors and residuals when we simulate the impact of black-swan events?2 By intentionally causing outages in order to refine our models. I’ll be talking a lot more about this concept in the coming weeks. But hold onto it for now, as there are some other components to cover first.

Tweak, update, reproduce
Let’s cover a few more downsides of the Business Blackout model.3 The model is hard to reproduce or update. What if I need to try different model parameters? There’s no code to run! As the world and Internet change (as they both have since 2015), the ability to flexibly update models is increasingly important.4
What can we do to make this kind of structural analysis accessible and reproducible enough to guide and inform diverse decision-makers (government, industry, civil society, and beyond)? We need an open, structural model on top of which different simulations can be run and their results shared for reproducibility. As we’ll discussing in the coming weeks, this ‘spec’ sometimes collides with legitimate needs for privacy and secrecy, which range from individual privacy to national security. Again, hold on to this idea. There’s one more thing to cover.
Control points and systemic risk
One last critique of the Business Blackout model. While its approach to calculating economic reverberations of an Internet outage is fine-grained, its approach to the Internet itself is relatively coarse. The authors imagine an Internet-based attack, which is itself realistic, but the attack simply turns the power off. This sort of analysis might be helpful for Internet shutdowns of the sort we've seen in India and beyond, but the most dangerous Internet disruptions are more complex than the Internet being on or off.
Consider: On the morning of Thursday, June 8, 2021, Amazon.com was down. CNN was down. HBO, Pinterest, Spotify, GitHub, Reddit, Twitch, StackOverflow were all down. So was gov.uk, the UK's government website. What happened? A coordinated cyberattack? No, just human error at Fastly, the world's second-largest content delivery network (CDN).
CDN downtime can cause cascading failures—what Welburn & Strong (2019) call systemic risk. For example, even if the Financial Times does not directly use Fastly on their user-facing webpage, a build tool in their engineering supply chain may require a library that's stored on a Fastly server. As a result, a Fastly outage will bring down the Financial Times via its supply chain. Think of it this way: billions of web pages use thousands of different software supply chains, using some combination of the same hundreds of common tools, which are in turn delivered by some eleven CDNs. Disruptions at the base of this inverted pyramid can cause massive, and difficult-to-predict patterns of failure at the levels above.
This class of errors—systemic risks—are our primary concern. And CDNs are a wonderful example of how they happen: through interruptions or unexpected behavior in which David Clark calls “control points”—entities on whom downstream actions and services depend.
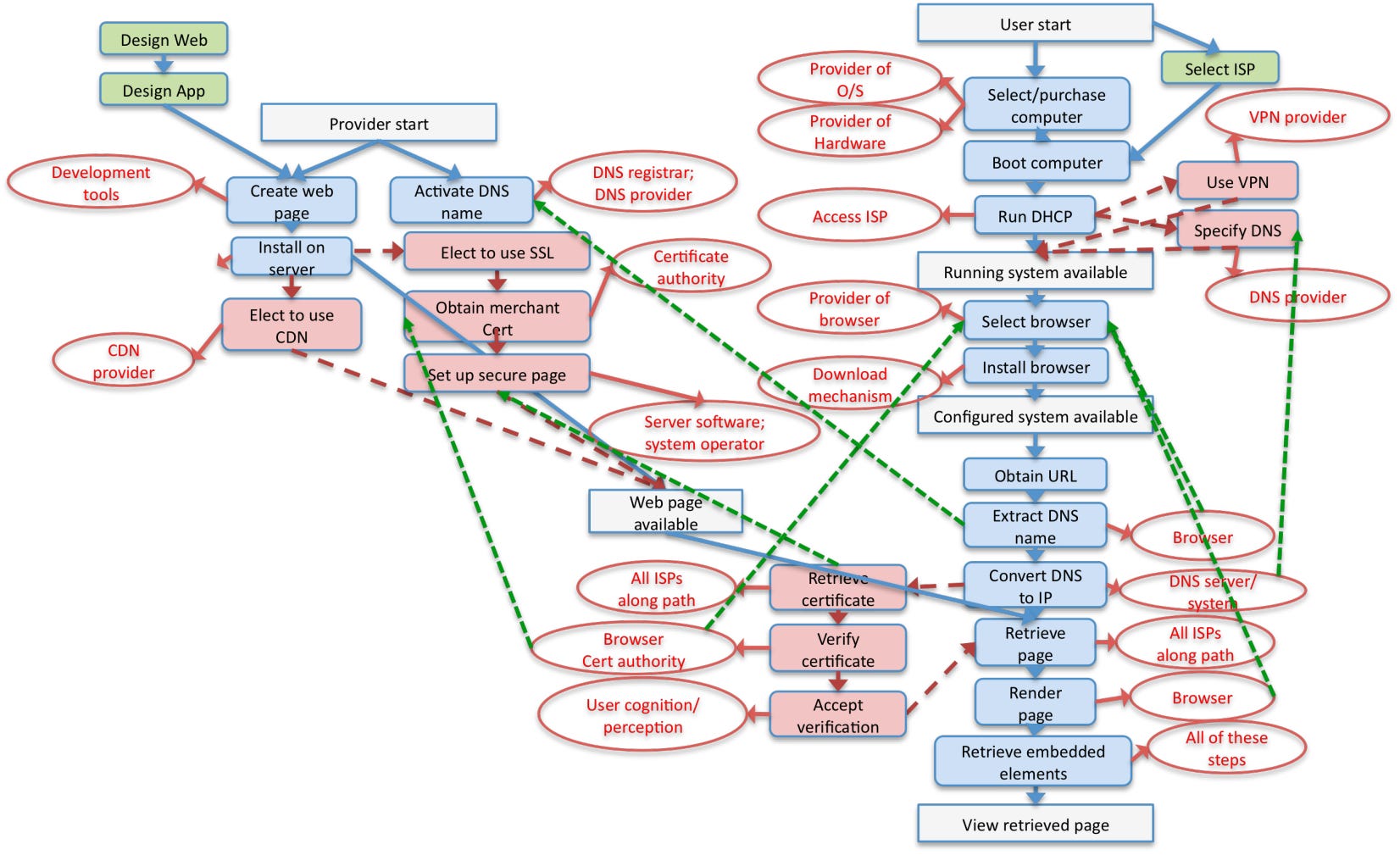
Consider the figure above. Visiting a webpage requires the coordination of many actors across diverse timescales. To ask meaningful hypothetical questions about the Internet, we must understand which particular actors create which particular patterns of dependency—who depends on whom, and for what? These questions are more fine-grained than the Internet being off in a certain region for a certain amount of time, but potentially much more wide-ranging in the (geographic, digital, economic, social, cultural) scale of their impact.
What now?
You may be asking yourself: how do we find the control points? How do we get the data we need at the level of detail we need it? You may also be remarking on how quickly the Internet changes—currently, 5G and satellite Internet may fundamentally rebalance connectivity of the global Internet. How do we get reliable, comprehensive data about this Internet as it shifts beneath our feet? This question, and perhaps a few you haven’t thought of yet, will animate next week’s discussion. I’ll see you then. EDIT: I’ll get back to this topic later.
This scenario highlights, if anything, that turning the Internet off even for a few days can produce unbelievably large costs to society. So the costs of the global Internet collapsing are unfathomable. But I take it you already believe me the stakes are high here, or you wouldn’t be reading the footnotes.
Black swan events are highly unlikely, highly impactful. As far as I know, this term was coined by Nassim Nicholas Taleb. The goal is not to predict particular events, but to build a robustness against them such that any black swan event makes the system stronger. Tabel calls this property antifragility.
Is the Internet antifragile? This is a core research question. If you have experience with questions like this one, do get in touch.
I’m sorry to the authors of Business Blackout. It’s good work. I’m picking on it because it’s good—it highlights what’s missing from the state of the art even when you peel methodological problems away.
As I've already argued, a stable Internet is a prerequisite for global stability. We’re pretty “locked-in” to this Internet, so disruptions to it would be mega-bad, as I’ve argued. But even beyond that historical circumstance, I believe a singular, shared system of communication is a global, pre-competitive good, conceptually similar to global trade.